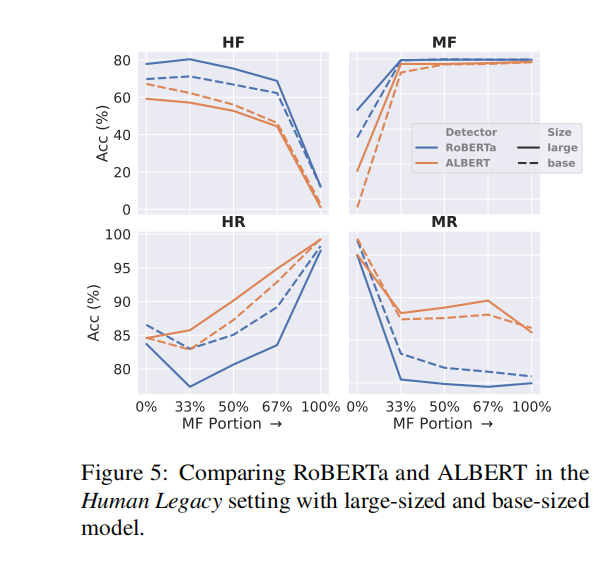
【好书推荐7】《机器学习平台架构实战》
- 写在最前面
- 《机器学习平台架构实战》
- 编辑推荐
- 内容简介
- 作者简介
- 目 录
- 前 言
- 本书读者
- 内容介绍
- 充分利用本书
- 下载示例代码文件
- 下载彩色图像
- 本书约定

写在最前面
🌟 感谢大家的陪伴和支持,2024年争取每周二开展粉丝福利送书活动,欢迎关注 ~
第7波福利感谢 清华出版社 的大力支持
🚀 本期活动为大家带来的是 【好书推荐7】《机器学习平台架构实战》
京东:链接
🌈 评论区抽出两位小伙伴免费包邮送出:此文章下任意评论,即可参与抽取书籍活动!ps:每人支持最多3条评论。
抽奖结果将在上一期活动评论区、新一期送书活动最前方展示。
🎉恭喜上期活动中奖粉丝:Orchid and Cactus.、是店小二呀,看到后请vx私信联系。

《机器学习平台架构实战》
编辑推荐
随着人工智能和机器学习在许多行业中应用得越来越普遍,对能够将业务需求转化为机器学习解决方案并能够设计机器学习技术平台的机器学习解决方案架构师的需求在不断增加。本书旨在通过帮助人们学习机器学习概念、算法、系统架构模式和机器学习工具来解决业务和技术挑战,重点是企业环境中的大规模机器学习系统架构和操作。
内容简介
《机器学习平台架构实战》详细阐述了与机器学习平台架构相关的基本解决方案,主要包括机器学习和机器学习解决方案架构,机器学习的业务用例,机器学习算法,机器学习的数据管理,开源机器学习库,Kubernetes容器编排基础设施管理,开源机器学习平台,使用AWS机器学习服务构建数据科学环境,使用AWS机器学习服务构建企业机器学习架构,高级机器学习工程,机器学习治理、偏差、可解释性和隐私,使用人工智能服务和机器学习平台构建机器学习解决方案等内容。此外,本书还提供了相应的示例、代码,以帮助读者进一步理解相关方案的实现过程。
作者简介
戴维·平是一位资深技术领导者,在技术和金融服务行业拥有超过25年的经验。他的技术重点领域包括云架构、企业机器学习平台设计、大规模的模型训练、智能文档处理、智能媒体处理、智能搜索和数据平台。他目前在AWS领导一个人工智能/机器学习解决方案架构团队,帮助全球公司在AWS云中设计和构建人工智能/机器学习解决方案。在加入AWS之前,David在Credit Suisse和JPMorgan担任过多种高级技术领导职务。他的职业生涯始于英特尔的软件工程师。David拥有康奈尔大学的工程学位。
目 录
第1篇 使用机器学习解决方案架构解决业务挑战
第1章 机器学习和机器学习解决方案架构 3
1.1 人工智能和机器学习的定义 4
1.2 监督机器学习 4
1.3 无监督机器学习 6
1.4 强化学习 8
1.5 机器学习与传统软件 9
1.6 机器学习生命周期 11
1.6.1 业务理解和机器学习问题框架 13
1.6.2 数据理解和数据准备 13
1.6.3 模型训练和评估 14
1.6.4 模型部署 14
1.6.5 模型监控 14
1.6.6 业务指标跟踪 15
1.7 机器学习的挑战 15
1.8 机器学习解决方案架构 16
1.8.1 业务理解和机器学习转型 17
1.8.2 机器学习技术的识别和验证 18
1.8.3 系统架构设计与实现 18
1.8.4 机器学习平台工作流自动化 19
1.8.5 安全性和合规性 19
1.9 小测试 20
1.10 小结 21
第2章 机器学习的业务用例 23
2.1 金融服务中的机器学习用例 23
2.1.1 资本市场前台 24
2.1.2 资本市场后台运营 28
2.1.3 风险管理和欺诈检测 31
2.2 媒体和娱乐领域的机器学习用例 38
2.2.1 内容开发和制作 39
2.2.2 内容管理和发现 39
2.2.3 内容分发和客户参与 40
2.3 医疗保健和生命科学领域的机器学习用例 41
2.3.1 医学影像分析 42
2.3.2 药物发现 43
2.3.3 医疗数据管理 44
2.4 制造业中的机器学习用例 45
2.4.1 工程和产品设计 46
2.4.2 制造运营—产品质量和产量 47
2.4.3 制造运营—机器维护 47
2.5 零售业中的机器学习用例 48
2.5.1 产品搜索和发现 48
2.5.2 目标市场营销 49
2.5.3 情绪分析 50
2.5.4 产品需求预测 50
2.6 机器学习用例识别练习 51
2.7 小结 52
第2篇 机器学习的科学、工具和基础设施平台
第3章 机器学习算法 55
3.1 技术要求 55
3.2 机器学习的原理 56
3.3 机器学习算法概述 58
3.3.1 选择机器学习算法时的注意事项 58
3.3.2 机器学习算法类型 59
3.4 分类和回归问题的算法 59
3.4.1 线性回归算法 59
3.4.2 逻辑回归算法 60
3.4.3 决策树算法 60
3.4.4 随机森林算法 62
3.4.5 梯度提升机和XGBoost算法 64
3.4.6 K最近邻算法 65
3.4.7 多层感知器网络 65
3.4.8 聚类算法 68
3.4.9 K-means算法 68
3.5 时间序列分析算法 68
3.5.1 ARIMA算法 69
3.5.2 DeepAR算法 70
3.6 推荐算法 70
3.6.1 协同过滤算法 71
3.6.2 多臂老虎机/上下文老虎机算法 71
3.7 计算机视觉问题的算法 72
3.7.1 卷积神经网络 72
3.7.2 残差网络 73
3.8 自然语言处理问题的算法 74
3.8.1 Word2Vec 76
3.8.2 循环神经网络和长期短期记忆 77
3.8.3 BERT 78
3.8.4 GPT 82
3.8.5 潜在狄利克雷分配算法 82
3.8.6 生成模型 84
3.8.7 生成对抗网络 84
3.9 动手练习 85
3.9.1 问题陈述 85
3.9.2 数据集描述 86
3.9.3 设置Jupyter Notebook环境 86
3.9.4 运行练习 88
3.10 小结 93
第4章 机器学习的数据管理 95
4.1 技术要求 95
4.2 机器学习的数据管理注意事项 96
4.3 机器学习的数据管理架构 98
4.4 数据存储和管理 100
4.4.1 数据湖 100
4.4.2 AWS Lake Formation 101
4.5 数据提取 102
4.5.1 决定数据提取工具时的注意事项 102
4.5.2 Kinesis Firehose 103
4.5.3 AWS Glue 104
4.5.4 AWS Lambda 105
4.6 数据目录 105
4.6.1 采用数据目录技术的关键考虑因素 105
4.6.2 AWS Glue目录 106
4.7 数据处理 106
4.7.1 数据处理技术的关键要求 106
4.7.2 AWS Glue ETL 107
4.7.3 Amazon Elastic Map Reduce 107
4.7.4 AWS Lambda数据处理 107
4.8 数据版本控制 107
4.8.1 S3分区 108
4.8.2 专用数据版本工具 108
4.9 机器学习特征存储 108
4.10 供客户使用的数据服务 109
4.10.1 通过API使用 109
4.10.2 通过数据复制使用 109
4.11 数据管道 109
4.11.1 AWS Glue工作流 110
4.11.2 AWS步骤函数 110
4.12 身份验证和授权 110
4.13 数据治理 111
4.14 动手练习—机器学习的数据管理 113
4.14.1 使用Lake Formation创建数据湖 114
4.14.2 创建数据提取管道 115
4.14.3 创建Glue目录 116
4.14.4 在数据湖中发现和查询数据 118
4.14.5 创建Amazon Glue ETL作业以处理机器学习数据 119
4.14.6 使用Glue工作流构建数据管道 123
4.15 小结 124
第5章 开源机器学习库 125
5.1 技术要求 125
5.2 开源机器学习库的核心功能 126
5.3 了解scikit-learn机器学习库 126
5.3.1 安装scikit-learn 127
5.3.2 scikit-learn的核心组件 127
5.4 了解Apache Spark机器学习机器学习库 129
5.4.1 安装Spark ML 131
5.4.2 Spark机器学习库的核心组件 131
5.5 了解TensorFlow深度学习库 134
5.5.1 安装TensorFlow 136
5.5.2 TensorFlow的核心组件 136
5.6 动手练习—训练TensorFlow模型 138
5.7 了解PyTorch 深度学习库 141
5.7.1 安装PyTorch 141
5.7.2 PyTorch的核心组件 142
5.8 动手练习—构建和训练PyTorch模型 143
5.9 小结 146
第6章 Kubernetes容器编排基础设施管理 147
6.1 技术要求 147
6.2 容器介绍 147
6.3 Kubernetes概述和核心概念 149
6.4 Kubernetes网络 156
6.4.1 Kubernetes网络通信流程 156
6.4.2 从集群外部访问Pod或服务的选项 158
6.4.3 服务网格 161
6.5 Kubernetes安全和访问控制 163
6.5.1 网络安全 163
6.5.2 API的身份验证和授权 164
6.5.3 在Kubernetes上运行机器学习工作负载 168
6.6 动手练习—在AWS上构建Kubernetes基础设施 169
6.6.1 问题陈述 169
6.6.2 操作指导 169
6.7 小结 175
第3篇 企业机器学习平台的技术架构设计和监管注意事项
第7章 开源机器学习平台 179
7.1 技术要求 179
7.2 机器学习平台的核心组件 179
7.3 用于构建机器学习平台的开源技术 180
7.3.1 将Kubeflow用于数据科学环境 181
7.3.2 搭建模型训练环境 184
7.3.3 使用模型注册表注册模型 186
7.3.4 MLflow模型注册表 186
7.3.5 使用模型服务框架 188
7.3.6 Gunicorn和Flask推理引擎 188
7.3.7 TensorFlow Serving框架 189
7.3.8 TorchServe服务框架 191
7.3.9 KFServing框架 192
7.3.10 Seldon Core 194
7.3.11 自动化机器学习管道工作流程 197
7.3.12 Apache Airflow 197
7.3.13 Kubeflow Pipelines 199
7.4 动手练习—使用开源技术构建数据科学架构 201
7.4.1 第1部分—安装Kubeflow 201
7.4.2 第2部分—跟踪实验和管理模型 206
7.4.3 第3部分—使用机器学习管道实现自动化 213
7.4.4 授予命名空间服务账户访问Istio服务的权限 214
7.4.5 创建自动化管道 215
7.5 小结 225
第8章 使用AWS机器学习服务构建数据科学环境 227
8.1 技术要求 227
8.2 使用SageMaker的数据科学环境架构 228
8.2.1 SageMaker Studio 229
8.2.2 SageMaker Processing 230
8.2.3 SageMaker Training服务 232
8.2.4 SageMaker Tuning 233
8.2.5 SageMaker Experiments 234
8.2.6 SageMaker Hosting 234
8.3 动手练习—使用AWS服务构建数据科学环境 235
8.3.1 问题陈述 235
8.3.2 数据集 235
8.3.3 操作步骤说明 235
8.3.4 设置SageMaker Studio 235
8.3.5 设置CodeCommit 237
8.3.6 在Jupyter Notebook中训练BERT模型 238
8.3.7 使用SageMaker Training服务训练BERT模型 244
8.3.8 部署模型 247
8.3.9 将源代码保存到CodeCommit存储库 249
8.4 小结 249
第9章 使用AWS机器学习服务构建企业机器学习架构 251
9.1 技术要求 251
9.2 企业机器学习平台的关键要求 252
9.3 企业机器学习架构模式概述 253
9.4 模型训练环境 255
9.4.1 模型训练引擎 256
9.4.2 自动化支持 257
9.4.3 模型训练生命周期管理 259
9.5 模型托管环境深入研究 259
9.5.1 推理引擎 260
9.5.2 身份验证和安全控制 263
9.5.3 监控和日志记录 264
9.6 为机器学习工作流采用机器学习运维架构 264
9.6.1 机器学习运维架构的组件 265
9.6.2 监控和记录 269
9.6.3 模型训练监控 269
9.6.4 模型端点监控 272
9.6.5 机器学习管道监控 276
9.6.6 服务配置管理 277
9.7 动手练习—在AWS上构建机器学习运维管道 281
9.7.1 为机器学习培训管道创建CloudFormation模板 282
9.7.2 为CodePipeline训练管道创建CloudFormation模板 285
9.7.3 通过事件启动CodePipeline执行 286
9.7.4 为机器学习部署管道创建CloudFormation模板 287
9.8 小结 290
第10章 高级机器学习工程 291
10.1 技术要求 291
10.2 通过分布式训练方式训练大规模模型 291
10.3 使用数据并行进行分布式模型训练 293
10.3.1 参数服务器概述 294
10.3.2 在框架中实现参数服务器 295
10.3.3 AllReduce概述 296
10.3.4 在框架中实现AllReduce和Ring AllReduce 297
10.4 使用模型并行进行分布式模型训练 298
10.4.1 朴素模型并行性概述 299
10.4.2 管道模型并行性概述 300
10.4.3 张量并行概述 302
10.4.4 实现模型并行训练 303
10.4.5 Megatron-LM概述 303
10.4.6 DeepSpeed概述 305
10.4.7 SageMaker分布式训练库概述 306
10.5 实现低延迟模型推理 307
10.5.1 模型推理的工作原理和可优化的机会 307
10.5.2 硬件加速 308
10.5.3 模型优化 310
10.5.4 图和算子优化 312
10.5.5 模型编译器 314
10.5.6 推理引擎优化 315
10.6 动手练习—使用PyTorch运行分布式模型训练 316
10.6.1 修改训练脚本 316
10.6.2 修改train()函数 317
10.6.3 修改get_data_loader()函数 318
10.6.4 为多设备服务器结点添加多处理启动支持 318
10.6.5 修改和运行启动器notebook 318
10.7 小结 319
第11章 机器学习治理、偏差、可解释性和隐私 321
11.1 技术要求 321
11.2 机器学习治理的定义和实施原因 322
11.2.1 围绕模型风险管理的监管环境 322
11.2.2 机器学习模型风险的常见原因 323
11.3 了解机器学习治理框架 324
11.4 了解机器学习偏差和可解释性 325
11.4.1 偏差检测和减少 325
11.4.2 机器学习可解释性技术 327
11.4.3 LIME 327
11.4.4 SHAP 328
11.5 设计用于治理的机器学习平台 329
11.5.1 数据和模型文档 330
11.5.2 模型清单 331
11.5.3 模型监控 332
11.5.4 变更管理控制 333
11.5.5 世系和可重复性 333
11.5.6 可观察性和审计 333
11.5.7 安全和隐私保护 334
11.5.8 差分隐私 335
11.6 动手练习—检测偏差、模型可解释性和训练隐私保护模型 338
11.6.1 方案概述 338
11.6.2 检测训练数据集中的偏差 339
11.6.3 解释训练模型的特征重要性 342
11.6.4 训练隐私保护模型 343
11.7 小结 345
第12章 使用人工智能服务和机器学习平台构建机器学习解决方案 347
12.1 技术要求 347
12.2 人工智能服务的定义 348
12.3 AWS人工智能服务概述 348
12.3.1 Amazon Comprehend 349
12.3.2 Amazon Textract 351
12.3.3 Amazon Rekognition 352
12.3.4 Amazon Transcribe 354
12.3.5 Amazon Personalize 355
12.3.6 Amazon Lex 357
12.3.7 Amazon Kendra 358
12.3.8 针对机器学习用例评估AWS人工智能服务 359
12.4 使用人工智能服务构建智能解决方案 360
12.4.1 自动化贷款文件验证和数据提取 360
12.4.2 贷款文件分类工作流程 362
12.4.3 贷款数据处理流程 363
12.4.4 媒体处理和分析工作流程 363
12.4.5 电商产品推荐 365
12.4.6 通过智能搜索实现客户自助服务自动化 367
12.5 为人工智能服务设计机器学习运维架构 368
12.5.1 人工智能服务和机器学习运维的AWS账户设置策略 369
12.5.2 跨环境的代码推广 371
12.5.3 监控人工智能服务的运营指标 371
12.6 动手练习—使用人工智能服务运行机器学习任务 372
12.7 小结 376
前 言
随着人工智能和机器学习在许多行业中应用得越来越普遍,对能够将业务需求转化为机器学习解决方案并能够设计机器学习技术平台的机器学习解决方案架构师的需求在不断增加。本书旨在通过帮助人们学习机器学习概念、算法、系统架构模式和机器学习工具来解决业务和技术挑战,重点是企业环境中的大规模机器学习系统架构和操作。
本书首先介绍与机器学习和业务相关的基础知识,如机器学习的类型、业务用例和机器学习算法。然后深入研究机器学习的数据管理以及用于构建机器学习数据管理架构的各种AWS服务。
在深入介绍数据管理之后,本书重点介绍了构建机器学习平台的两种技术:使用Kubernetes、Kubeflow、MLflow和Seldon Core等开源技术,以及使用托管机器学习服务,如Amazon SageMaker、Step Functions和CodePipeline。
然后,本书进入高级机器学习工程主题,包括分布式模型训练和低延迟模型服务,以满足大规模的模型训练和高性能模型服务需求。
治理和隐私是在生产环境中运行模型的重要考虑因素。本书还将介绍机器学习治理要求以及机器学习平台如何在文档、模型清单、偏差检测、模型可解释性和模型隐私等方面支持机器学习治理。
构建基于机器学习的解决方案并不总是需要从头开始构建机器学习模型或基础设施。本书的最后一章还介绍了AWS AI服务以及这些AI服务可以帮助解决的问题,你将了解一些AI服务的核心功能,以及可以在哪些地方使用它们来构建基于机器学习的业务应用程序。
在本书结束时,你将熟悉机器学习解决方案和基础架构的各种业务、数据科学和技术领域。你将能够清晰了解构建企业机器学习平台的架构模式和注意事项,并使用各种开源和AWS技术培养动手技能。本书还可以帮助你准备与机器学习架构相关的工作面试。
本书读者
本书主要面向两类读者:开发者和云架构师,他们寻求技术指导和实践材料以成为机器学习解决方案架构师,或者成为经验丰富的机器学习架构从业者和数据科学家,以更广泛地了解行业机器学习用例、企业数据和机器学习架构模式、数据管理和机器学习工具、机器学习治理和高级机器学习工程技术等。
本书还可以使希望了解数据管理和云系统架构如何融入整个机器学习平台架构的数据工程师和云系统管理员受益。
本书假设你具备一定的Python编程知识并熟悉AWS服务。其中一些章节是为机器学习初学者设计的,用于学习核心的机器学习基础知识,这些知识可能与经验丰富的机器学习从业者已经掌握的知识重叠。
内容介绍
本书分为3篇,共12章。具体内容如下。
第1篇:使用机器学习解决方案架构解决业务挑战,包括第1~2章。
第1章“机器学习和机器学习解决方案架构”,详细阐释机器学习的核心概念(包括监督学习、无监督学习、强化学习、机器学习生命周期),探讨机器学习的挑战和机器学习解决方案架构功能等。
第2章“机器学习的业务用例”,讨论金融服务、媒体和娱乐、医疗保健和生命科学、制造业和零售领域的核心业务基础、工作流程和常见的机器学习用例。
第2篇:机器学习的科学、工具和基础设施平台,包括第3~6章。
第3章“机器学习算法”,详细介绍用于分类、回归、聚类、时间序列分析、推荐、计算机视觉、自然语言处理和数据生成的常见机器学习和深度学习算法。你将获得在本地机器上设置Jupyter服务器和构建机器学习模型的实践经验。
第4章“机器学习的数据管理”,涵盖平台功能、系统架构和用于构建机器学习数据管理功能的AWS工具。你还将掌握使用AWS服务开发为机器学习构建数据管理管道的实践技能。
第5章“开源机器学习库”,详细介绍scikit-learn、Apache Spark机器学习和TensorFlow的核心特性,以及如何使用这些机器学习库进行数据准备、模型训练和模型服务。你还将练习如何使用TensorFlow和PyTorch构建深度学习模型。
第6章“Kubernetes容器编排基础设施管理”,介绍容器、Kubernetes概念、Kubernetes网络和Kubernetes安全性。Kubernetes是用于构建开源机器学习解决方案的核心开源基础设施。你还将练习如何在AWS EKS上设置 Kubernetes平台并在Kubernetes中部署机器学习工作负载。
第3篇:企业机器学习平台的技术架构设计和监管注意事项,包括第7~12章。
第7章“开源机器学习平台”,阐释Kubeflow、MLflow、AirFlow、Seldon Core等各种开源机器学习平台技术的核心概念和技术细节。本章还介绍如何使用这些技术来构建数据科学环境和机器学习自动化管道,并提供使用这些开源技术进行开发的说明。
第8章“使用AWS机器学习服务构建数据科学环境”,介绍用于构建数据科学环境的各种AWS托管服务,包括Amazon SageMaker、Amazon ECR和Amazon CodeCommit等。你还将获得这些服务的实践经验,以配置用于实验和模型训练的数据科学环境。
第9章“使用AWS机器学习服务构建企业机器学习架构”,讨论企业机器学习平台的核心要求,以及在AWS上构建企业机器学习平台的架构模式,并深入探讨SageMaker和其他各种核心机器学习功能的AWS服务。本章还提供在AWS上构建机器学习运维管道的动手练习。
第10章“高级机器学习工程”,涵盖大规模分布式模型训练的核心概念和技术,如使用DeepSpeed和PyTorch DistributeDataParallel进行数据并行和 模型并行训练。还将深入探讨低延迟模型推理的技术方法,如使用硬件加速、模型优化以及图和算子优化。本章还将使用SageMaker训练集群进行分布式数据并行模型训练。
第11章“机器学习治理、偏差、可解释性和隐私”,将详细讨论生产模型部署的机器学习治理、偏差、可解释性和隐私要求等。你还将练习使用SageMaker Clarify和PyTorch Opacus来检测偏差和训练隐私保护模型等。
第12章“使用人工智能服务和机器学习平台构建机器学习解决方案”,详细介绍AWS提供的人工智能服务和架构模式,以及如何将这些人工智能服务集成到机器学习支持的业务应用程序中。
充分利用本书
本书涵盖的软硬件和操作系统需求如表P.1所示。
表P.1 本书涵盖的软硬件和操作系统需求
本书涵盖的软硬件 操作系统需求
Jupyter Notebook Windows、macOS或Linux
Python
TensorFlow
PyTorch
如果你使用本书的数字版本,则建议你自己输入代码或从本书的GitHub存储库访问代码(下一节将提供链接)。这样做将帮助你避免复制和粘贴代码可能带来的潜在错误。
下载示例代码文件
本书随附的代码可以在GitHub存储库中找到,其网址如下:
https://github.com/PacktPublishing/The-Machine-Learning-Solutions-Architect-Handbook
如果代码有更新,那么更新将在该GitHub存储库中给出。
下载彩色图像
我们还提供了一个PDF文件,其中包含本书中使用的屏幕截图/图表的彩色图像。你可以通过以下地址进行下载:
https://static.packt-cdn.com/downloads/9781801072168_ColorImages.pdf
本书约定
本书中使用了许多文本约定。
(1)有关代码块的设置如下:
import pandas as pd
churn_data = pd.read_csv("churn.csv")
churn_data.head()
(2)要突出代码块时,相关内容将加粗显示:
# 以下命令可以计算特征的各种统计信息
churn_data.describe()
# 以下命令可以显示不同特征的直方图
# 可以通过替换列名称来绘制其他特征的直方图
churn_data.hist(['CreditScore', 'Age', 'Balance'])
# 以下命令可以计算特征之间的相关性
churn_data.corr()
(3)任何命令行输入或输出都采用如下所示的粗体代码形式:
! pip3 install --upgrade tensorflow
(4)术语或重要单词采用中英文对照形式,在括号内保留其英文原文。示例如下:
为了优化这个目标,机器学习算法会迭代和处理大量的历史销售数据(训练数据),并调整其内部模型参数,直到它可以最小化预测值和实际值之间的差异。这个寻找最优模型参数的过程称为优化(Optimization),执行优化的数学程序称为优化器(Optimizer)。
(5)对于界面词汇或专有名词将保留英文原文,在括号内添加其中文译文。示例如下:
在“In [ ]:”右边的部分称为单元格,可以在单元格中输入代码。要运行单元格中的代码,可以单击工具栏上的Run(运行)按钮。要添加新单元格,可以单击工具栏上的 (加号)按钮。
(6)本书还使用了以下两个图标:
表示警告或重要的注意事项。
表示提示或小技巧。